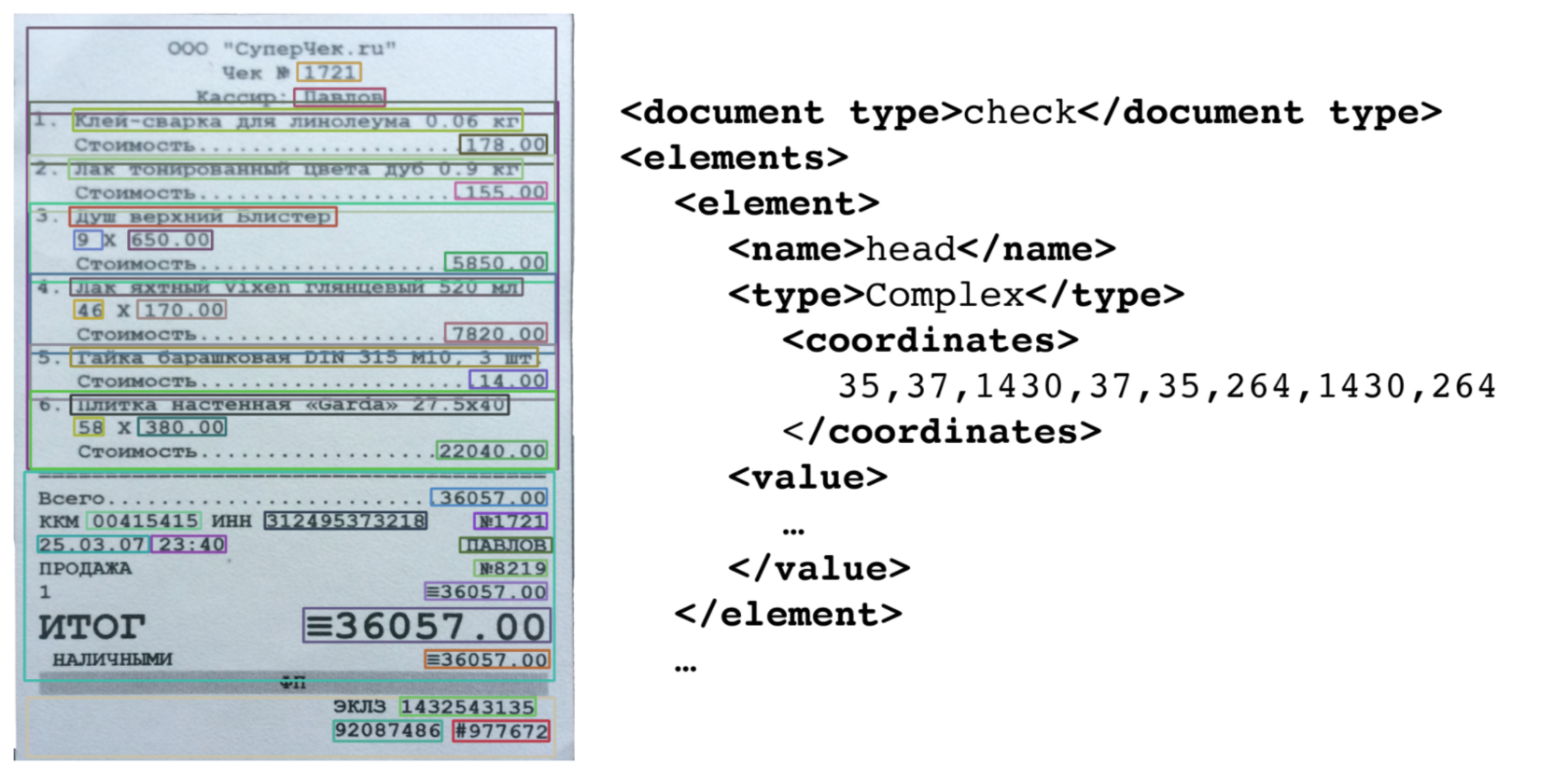
Описание исходной ситуации:
- высокая эффективность документооборота с минимальным числом ошибок предполагает хранение электронных версий документов и быструю оцифровку печатных версий документов.
- обработка печатных версий документов предполагается перевод изображений в электронное структурированное представление с высокой точностью.
- используемый для этого бизнес-процесс не подходит для масштабирования, так как применяется ручной труд для распознавания печатных версий документов.
- по этой причине возникали значительные риски для планируемого роста бизнеса
Цели проекта:
- создание системы распознавания основных полей документов с достаточных уровнем качества
- создание инструмента формирования новых форматов документов.
Решение MIL Team: использование существующих решений команды в области детекции и распознавания текста на изображениях, основанных на нейросетевых моделях, позволило в короткие сроки реализовать решение с требуемым уровнем качества.
Итоги:
Построено решения для автоматизации распознавания:
- Чеков и квитанций;
- Счет-фактур (invoice);
- Заказ-наряда;
- Договора подряда.
Для построения модели были использованы:
- Размеченный шаблон документа;
- Опорные поля документа с их характеристиками;
- Набор изображений документов.
Результаты моделирования:
- Модель выделения символов OCR;
- Модель поиска блоков текста Text Detection;
- Модель распознавания таблиц Table Detection;
- Модель построения электронной версии документа.
Заказчик: Финансы, Бухгалтерия
Технологический стек: TensorFlow, Python, Flask.