Motivation for the customer to launch the project:
active noise reduction systems, including those based on neural networks, are actively used in various services for audio and video communications. Most of these systems cope well with the task of noise reduction, mainly in situations with a high level of the useful signal and a low level of noise. The goal was to build real-time system capable of clearing audio recordings from noise within specified limitations.
Description of the initial situation:
Project goals:
Improving the quality of noise reduction models in the case of extremely low SNR (signal-to-noise ratio).
MIL Team solution:
improving existing solutions and creating our own models that show a high increase in terms of generally accepted metrics for assessing the quality of audio recordings (PESQ, SDR) and speech recognition error (WER) for audio recordings with a high level of noise compared to speech (SNR from -10) .
To build the model we used:
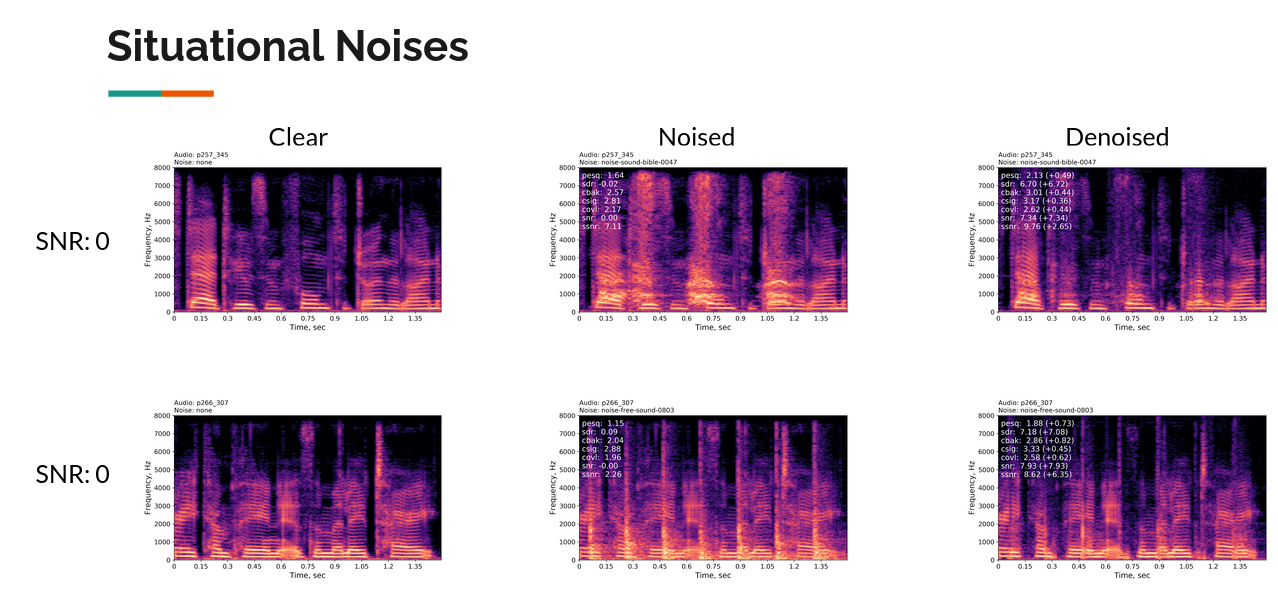
Simulation results:
Obtained two promising WaveUnet models with following metrics:
8kHz: PESQ + 0.3(average), +0.3(0 SNR),
SDR +6.3(average), +9.5(0 SNR), 15.98 MMACs [Best Metrics]
8kHz + Dilations + DepthWise: PESQ + 0.3(average), +0.3(0 SNR),
SDR +6.2(average), +9.1(0 SNR), 7.49 MMACs [Smallest MAC count]
Obtained 16kHz model which is not smallest in terms of MACs, nor best in metrics, but perceptual quality is better due to higher sampling rate:
16kHz + Dilations + DepthWise: PESQ + 0.3(average), +0.3(0 SNR),
SDR +5.4(average), +8.2(0 SNR), 14.6 MMACs [Better perceptually]
Customer: Polyn Technology
Technology stack: Python (PyTorch, scipy, librosa)
active noise reduction systems, including those based on neural networks, are actively used in various services for audio and video communications. Most of these systems cope well with the task of noise reduction, mainly in situations with a high level of the useful signal and a low level of noise. The goal was to build real-time system capable of clearing audio recordings from noise within specified limitations.
Description of the initial situation:
- most existing speech enhancement models work well at high SNRs;
- there is a small number of generally accepted datasets for speech enhancement;
- in addition to well-known metrics such as SDR and PESQ, a subjective assessment of the sound quality of the resulting audio recording is also important;
- For the applicability of simulation results in real time, it is important to minimize the size of the window in the future (lookahead), which is used to predict the current value.
Project goals:
Improving the quality of noise reduction models in the case of extremely low SNR (signal-to-noise ratio).
MIL Team solution:
improving existing solutions and creating our own models that show a high increase in terms of generally accepted metrics for assessing the quality of audio recordings (PESQ, SDR) and speech recognition error (WER) for audio recordings with a high level of noise compared to speech (SNR from -10) .
To build the model we used:
- open datasets of audio recordings with speech Voicebank and Librispeech;
- open datasets of audio recordings with noise DEMAND, MUSAN.
Simulation results:
Obtained two promising WaveUnet models with following metrics:
8kHz: PESQ + 0.3(average), +0.3(0 SNR),
SDR +6.3(average), +9.5(0 SNR), 15.98 MMACs [Best Metrics]
8kHz + Dilations + DepthWise: PESQ + 0.3(average), +0.3(0 SNR),
SDR +6.2(average), +9.1(0 SNR), 7.49 MMACs [Smallest MAC count]
Obtained 16kHz model which is not smallest in terms of MACs, nor best in metrics, but perceptual quality is better due to higher sampling rate:
16kHz + Dilations + DepthWise: PESQ + 0.3(average), +0.3(0 SNR),
SDR +5.4(average), +8.2(0 SNR), 14.6 MMACs [Better perceptually]
Customer: Polyn Technology
Technology stack: Python (PyTorch, scipy, librosa)